With release 1.8.3, Doxygen provides the ability to search through HTML using an external indexing tool and search engine. This has several advantages:
To avoid that everyone has to start writing their own indexer and search engine, Doxygen provides an example tool for each action: doxyindexer for indexing the data and doxysearch.cgi for searching through the index.
The data flow is shown in the following diagram:

The first step is to make the search engine available via a web server. If you use doxysearch.cgi this means making the CGI binary available from the web server (i.e. be able to run it from a browser via an URL starting with http:)
How to setup a web server is outside the scope of this document, but if you for instance have Apache installed, you could simply copy the doxysearch.cgi file from Doxygen's bin directory to the cgi-bin directory of the Apache web server. Read the apache documentation for details.
To test if doxysearch.cgi is accessible start your web browser and point to URL to the binary and add ?test at the end
http://yoursite.com/path/to/cgi/doxysearch.cgi?test
You should get the following message:
Test failed: cannot find search index doxysearch.db
If you use Internet Explorer you may be prompted to download a file, which will then contain this message.
Since we didn't create or install a doxysearch.db it is OK for the test to fail for this reason. How to correct this is discussed in the next section.
Before continuing with the next section add the above URL (without the ?test part) to the SEARCHENGINE_URL tag in Doxygen's configuration file:
SEARCHENGINE_URL = http://yoursite.com/path/to/cgi/doxysearch.cgi
To use the external search option, make sure the following options are enabled in Doxygen's configuration file:
SEARCHENGINE = YES SERVER_BASED_SEARCH = YES EXTERNAL_SEARCH = YES
This will make Doxygen generate a file called searchdata.xml in the output directory (configured with OUTPUT_DIRECTORY). You can change the file name (and location) with the SEARCHDATA_FILE option.
The next step is to put the raw search data into an index for efficient searching. You can use doxyindexer for this. Simply run it from the command line:
doxyindexer searchdata.xml
This will create a directory called doxysearch.db with some files in it. By default the directory will be created at the location from which doxyindexer was started, but you can change the directory using the -o option.
Copy the doxysearch.db directory to the same directory as where the doxysearch.cgi is located and rerun the browser test by pointing the browser to
http://yoursite.com/path/to/cgi/doxysearch.cgi?test
You should now get the following message:
Test successful.
Now you should be able to search for words and symbols from the HTML output.
In case you have more than one Doxygen project and these projects are related, it may be desirable to allow searching for words in all projects from within the documentation of any of the projects.
To make this possible all that is needed is to combine the search data for all projects into a single index, e.g. for two projects A and B for which the searchdata.xml is generated in directories project_A and project_B run:
doxyindexer project_A/searchdata.xml project_B/searchdata.xml
and then copy the resulting doxysearch.db to the directory where also doxysearch.cgi is located.
The searchdata.xml file doesn't contain any absolute paths or links, so how can the search results from multiple projects be linked back to the right documentation set? This is where the EXTERNAL_SEARCH_ID and EXTRA_SEARCH_MAPPINGS options come into play.
To be able to identify the different projects, one needs to set a unique ID using EXTERNAL_SEARCH_ID for each project.
To link the search results to the right project, you need to define a mapping per project using the EXTRA_SEARCH_MAPPINGS tag. With this option to can define the mapping from IDs of other projects to the (relative) location of documentation of those projects.
So for projects A and B the relevant part of the configuration file could look as follows:
project_A/Doxyfile ------------------ EXTERNAL_SEARCH_ID = A EXTRA_SEARCH_MAPPINGS = B=../../project_B/html
for project A and for project B
project_B/Doxyfile ------------------ EXTERNAL_SEARCH_ID = B EXTRA_SEARCH_MAPPINGS = A=../../project_A/html
with these settings, projects A and B can share the same search database, and the search results will link to the right documentation set.
When you modify the source code, you should re-run doxygen to get up to date documentation again. When using external searching you also need to update the search index by re-running doxyindexer. You could wrap the call to doxygen and doxyindexer together in a script to make this process easier.
Previous sections have assumed you use the tools doxyindexer and doxysearch.cgi to do the indexing and searching, but you could also write your own index and search tools if you like.
For this 3 interfaces are important
The next subsections describe these interfaces in more detail.
The search data produced by Doxygen follows the Solr XML index message format.
The input for the indexer is an XML file, which consists of one <add> tag containing multiple <doc> tags, which in turn contain multiple <field> tags.
Here is an example of one doc node, which contains the search data and meta data for one method:
<add>
...
<doc>
<field name="type">function</field>
<field name="name">QXmlReader::setDTDHandler</field>
<field name="args">(QXmlDTDHandler *handler)=0</field>
<field name="tag">qtools.tag</field>
<field name="url">de/df6/class_q_xml_reader.html#a0b24b1fe26a4c32a8032d68ee14d5dba</field>
<field name="keywords">setDTDHandler QXmlReader::setDTDHandler QXmlReader</field>
<field name="text">Sets the DTD handler to handler DTDHandler()</field>
</doc>
...
</add>
Each field has a name. The following field names are supported:
When the search engine is invoked from a Doxygen generated HTML page, a number of parameters are passed to via the query string.
The following fields are passed:
From the complete list of search results, the range [n*p - n*(p+1)-1] should be returned.
Here is an example of how a query looks like.
http://yoursite.com/path/to/cgi/doxysearch.cgi?q=list&n=20&p=1&cb=dummy
It represents a query for the word 'list' (q=list) requesting 20 search results (n=20), starting with the result number 20 (p=1) and using callback 'dummy' (cb=dummy):
When invoking the search engine as shown in the previous subsection, it should reply with the results. The format of the reply is JSON with padding, which is basically a JavaScript struct wrapped in a function call. The name of function should be the name of the callback (as passed with the cb field in the query).
With the example query as shown the previous subsection the main structure of the reply should look as follows:
dummy({
"hits":179,
"first":20,
"count":20,
"page":1,
"pages":9,
"query": "list",
"items":[
...
]})
The fields have the following meaning:
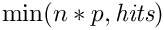 .
.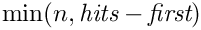
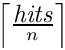 .
.Here is an example of how the element of the items array should look like:
{"type": "function",
"name": "QDir::entryInfoList(const QString &nameFilter, int filterSpec=DefaultFilter, int sortSpec=DefaultSort) const",
"tag": "qtools.tag",
"url": "d5/d8d/class_q_dir.html#a9439ea6b331957f38dbad981c4d050ef",
"fragments":[
"Returns a <span class=\"hl\">list</span> of QFileInfo objects for all files and directories...",
"... pointer to a QFileInfoList The <span class=\"hl\">list</span> is owned by the QDir object...",
"... to keep the entries of the <span class=\"hl\">list</span> after a subsequent call to this..."
]
},
The fields for such an item have the following meaning:
